Por qué Together.ai cambió la forma en que hago benchmarking de agentes de radiología
Antes de poder entrenar un modelo, tienes que saber cuál modelo merece ser entrenado.
Esa frase suena obvia, pero en la práctica es la parte que más se ignora.
Cuando empecé a construir agentes de control de calidad para reportes radiológicos, cometí el error clásico: elegí un modelo por reputación, lo integré directamente al flujo clínico, y asumí que funcionaría bien. Funcionó… más o menos. El problema es que "más o menos" no es un estándar aceptable cuando el agente tiene que detectar si el reporte menciona un ovario en un paciente masculino o si una lesión hepática de 28 mm quedó fuera de la conclusión.
Necesitaba benchmarking real. Y para eso necesitaba poder llamar a varios modelos, con casos clínicos reales, sin armar infraestructura desde cero para cada uno.
Ahí entró Together.ai.
El problema con el benchmarking de modelos en radiología
Comparar modelos de lenguaje para casos clínicos no es lo mismo que comparar chatbots generales. En radiología, los errores tienen categorías, severidades y consecuencias clínicas. Un error crítico —como confundir lateralidad o reportar un órgano que fue extirpado quirúrgicamente— no es equivalente a un error menor de formato.
Para hacer un benchmark útil necesitas:
- Casos clínicos con errores conocidos e intencionados (ground truth)
- Un prompt de sistema que defina reglas de evaluación clínica precisas
- Llamar a múltiples modelos con los mismos casos
- Medir precisión, recall y F1 por modelo, no solo "la respuesta suena bien"
- Calcular latencia y costo real para poder tomar decisiones de producción
Nada de esto requiere un modelo propietario. Pero sí requiere acceso fácil a múltiples modelos con una API unificada.
Together.ai: una API, docenas de modelos
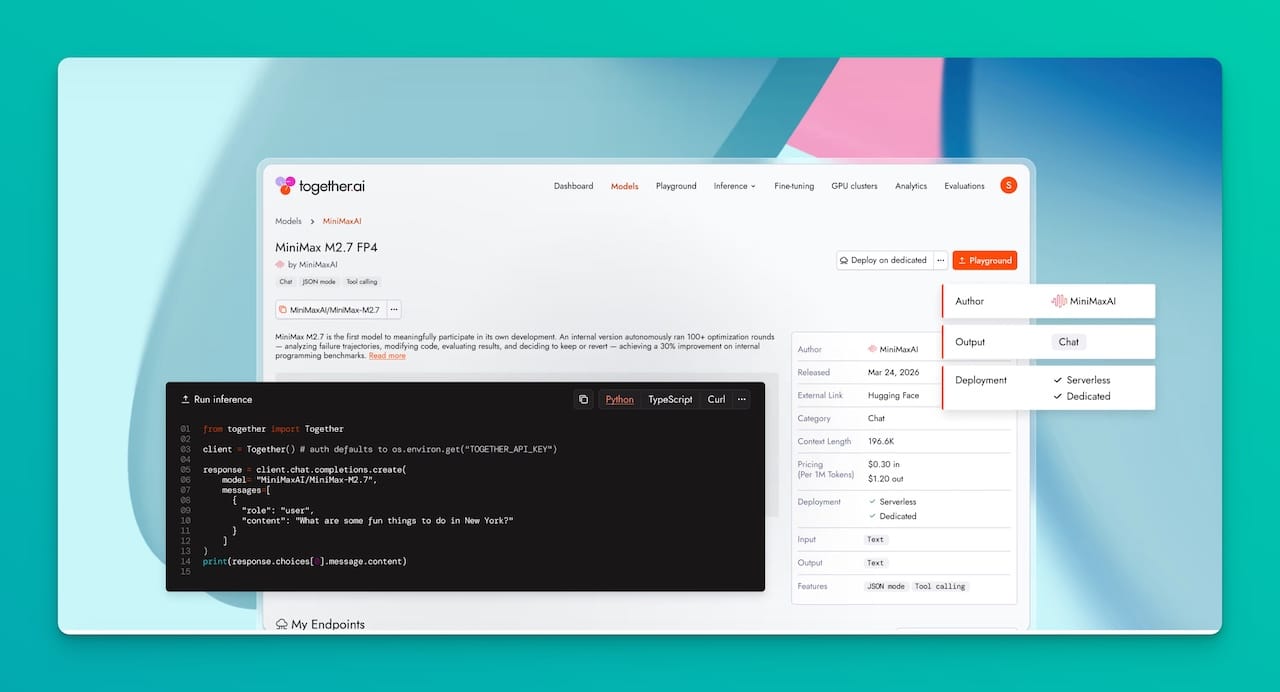
Together.ai es una plataforma de inferencia serverless que da acceso a modelos open-source de alto rendimiento —GPT-OSS, Mistral, LLaMA, Qwen, DeepSeek y muchos más— bajo una sola API compatible con el estándar OpenAI.
Lo que eso significa en la práctica: cambias el nombre del modelo en una línea de código y ya estás probando otro.
No hay que crear cuentas separadas, manejar diferentes formatos de respuesta, ni lidiar con SDKs distintos. El endpoint es el mismo. La estructura del request es la misma. Solo cambia el model.
Para benchmarking, eso es transformador.
Cómo lo usé en la práctica
Construí un benchmark con cinco casos clínicos de radiología, cada uno con errores conocidos clasificados según 24 reglas de control de calidad: errores críticos (órgano incorrecto para el sexo del paciente, lateralidad errónea, hallazgo no mencionado en la conclusión), errores mayores (mediciones vacías, lesión sin dimensiones, ausencia de contraste), y errores menores (sin mención de portabilidad, sin dosis de radiación).
El agente recibe cada reporte, lo analiza con el prompt de sistema, y devuelve un JSON estructurado con los errores detectados, severidad, evidencia textual y sugerencia de corrección.
Con Together.ai pude correr ese benchmark contra tres modelos —un modelo de 20B parámetros, uno de 120B y Mistral 3 14B— en paralelo, sobre los mismos cinco casos, midiendo:
- F1 score por caso y promedio global
- Latencia media y mínima
- Costo real por 800 estudios al mes (volumen representativo de una clínica mediana en Latinoamérica)
Los resultados mostraron diferencias significativas entre modelos que ningún "vistazo subjetivo" habría revelado: el modelo más costoso no era el más preciso. El más rápido tenía un recall aceptable para errores críticos pero fallaba en errores mayores. Y el más económico tenía una relación costo-F1 que lo hacía candidato serio para producción.
Sin Together.ai, esa comparación habría tomado semanas de integración. Con Together.ai, tomó horas.
Por qué el modelo serverless importa
La arquitectura serverless de Together.ai no es solo un detalle técnico. Tiene implicaciones concretas para proyectos clínicos:
Sin costo de infraestructura. No hay servidores que administrar, ni GPUs que alquilar, ni Docker containers que mantener para los modelos de inferencia. Pagas por token consumido, nada más.
Escalabilidad instantánea. Si mañana quieres correr el mismo benchmark con 500 casos en lugar de 5, la plataforma lo absorbe sin que toques nada. Para validaciones clínicas más amplias —que eventualmente son necesarias antes de producción— eso es crítico.
Ciclos de iteración cortos. En desarrollo de agentes clínicos, el ciclo es: hipótesis → prueba → ajuste de prompt → prueba → evaluación. Cada iteración que tarda horas en lugar de días acelera el aprendizaje clínico real.
Base para fine-tuning. Este es el punto que más me interesa. El benchmarking no es el destino; es el primer paso. Una vez que sabes qué modelo base tiene el mejor perfil para tu caso de uso, puedes tomar los mismos casos del benchmark —con sus errores conocidos y sus respuestas JSON correctas— y usarlos como datos de entrenamiento para fine-tuning. Together.ai también ofrece fine-tuning sobre sus modelos base. Es el mismo ecosistema, el mismo formato, la misma API.
Lo que aprendí sobre elegir modelos para agentes clínicos : F1 no es fórmula 1!
Después de correr benchmarks con varios modelos y casos, hay tres cosas que cambié en cómo pienso la selección:
El F1 importa más que el score subjetivo. Los modelos tienden a dar scores de 70-80/100 a casi cualquier reporte, incluso con errores graves. Lo que diferencia modelos es la capacidad de detectar errores específicos con alta precisión. Un modelo que detecta 7 de 10 errores esperados con 0 falsos positivos es mejor que uno que detecta 10 con 4 falsos positivos.
La latencia tiene contexto clínico. En un flujo de validación asincrónica, 3 segundos de latencia no importan. En un agente que revisa reportes en tiempo real mientras el radiólogo dicta, sí importa. Mide latencia con el contexto del flujo clínico en mente.
El siguiente paso: fine-tuning con datos propios
El benchmark no es el producto final. Es la selección del candidato.
Una vez identificado el modelo base con mejor perfil para detección de errores en reportes radiológicos, el siguiente paso es fine-tuning con casos propios del contexto latinoamericano: terminología clínica en español, patrones locales de dictado, errores frecuentes en la práctica real de radiología colombiana y centroamericana.
Together.ai facilita exactamente eso: el mismo ecosistema donde hiciste el benchmark es donde puedes entrenar. Los datos que generaste en el proceso de evaluación —reportes con errores conocidos, respuestas JSON correctas, clasificaciones clínicas— son los datos de entrenamiento.
Es un flujo coherente de principio a fin. Bienvenidos a la F1!
Miguel Angarita es radiólogo e implementador de IA clínica. Trabaja con clínicas y hospitales en Colombia y Centroamérica en la integración práctica de agentes de inteligencia artificial en flujos radiológicos. Es fundador de AngaritaRad.